Algorithm of Reinforcement Learning using RSL (Reinforcement Signal Learning)
Reinforcement Learning with Artificial Neural Networks is a powerful approach for decision-making in dynamic environments. It involves training an agent through trial and error using rewards as feedback. The Reinforcement Signal Learning (RSL) approach is a specific technique that enhances RL by improving how the agent processes reinforcement signals.
Algorithm of RL with ANN and RSL
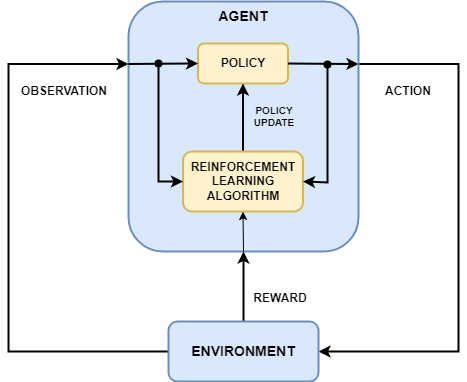
1. Initialize the Environment and the Agent
- Define the state space and action space .
- Initialize a policy , represented by a neural network with weights .
- Initialize the Q-function , which estimates the value of taking action a in state s.
- Initialize an empty replay buffer (if using experience replay).
2. Observe and Take Action
- The agent observes the initial state .
- Select an action at using the policy , which can be:
- Deterministic: .
- Stochastic (e.g., using ϵ-greedy or softmax exploration).
- Execute action at and move to the next state .
- Receive reward .
3. Reinforcement Signal Learning (RSL) for Reward Processing
- Traditional RL Reward: Use rt directly to update weights.
- RSL Enhanced Reward Processing:
- Apply normalization or adaptive scaling to .
- Use a reward shaping function to improve learning speed.
- Apply temporal discounting:
- If using advantage functions, compute:
- Update the experience buffer (if applicable).
4. Train the ANN (Policy or Q-network)
- Compute the target value:
- For Value-Based RL (Q-learning, DQN):
- Update Q-network using Mean Squared Error (MSE) loss:
- For Policy-Based RL (Policy Gradient, PPO, A2C):
- Compute policy gradient:
- Update weights using gradient ascent.
- For Value-Based RL (Q-learning, DQN):
5. Experience Replay (Optional)
- Store the tuple in memory.
- Sample minibatches from memory for training (DQN, DDQN, PPO).
- Use target networks for stability in Q-learning methods.
6. Repeat Until Convergence
- Continue interacting with the environment.
- Optimize the neural network based on updated rewards.
- Reduce exploration over time (ϵ-decay or entropy regularization).
Key Enhancements with RSL
- Adaptive reward shaping to prevent sparse rewards.
- Normalization of rewards to prevent instability.
- Temporal credit assignment to distribute reward signals over time.
- Gradient-based updates using adjusted reinforcement signals.
Below is a sample environment and training script for a Reinforcement Learning task in NVIDIA IsaacSim + IsaacLab. The sample includes commands for both playing (running the trained policy) and training the agent in the Isaac-Velocity-Rough-Unitree-Go1-v0 environment.
Isaac-Velocity-Rough-Unitree-Go1-v0
This environment, provided by IsaacSim + IsaacLab (NVIDIA), is designed for training a Unitree Go1 robot to navigate rough terrain at a specified velocity. The robot uses reinforcement learning methods from RSL RL. Below are sample commands to play a trained policy and to train a new policy from scratch or resume training.
Play
Use the following command to run the trained policy and observe its behavior in the environment:
isaaclab.bat -p scripts/reinforcement_learning/rsl_rl/play.py \
--task=Isaac-Velocity-Rough-Anymal-C-v0 \
--num_envs 1 \
--checkpoint D:\python-projects\IsaacLab\logs\rsl_rl\anymal_c_rough\2025-02-03_22-23-04\model_250.pt
Note: Update the environment name (Isaac-Velocity-Rough-Unitree-Go1-v0), checkpoint paths, and resume steps according to your project setup.
Train
Use the following command to start (or resume) training the policy:
isaaclab.bat -p scripts/reinforcement_learning/rsl_rl/train.py \
--task=Isaac-Velocity-Rough-Anymal-C-v0 \
--headless \
--resume=850
Make Your Business Online By The Best No—Code & No—Plugin Solution In The Market.
30 Day Money-Back Guarantee
Say goodbye to your low online sales rate!