

Fiction is All You Need / Shadow AGI
In the realm of natural language processing, the development of advanced chatbots and conversational agents has gained immense traction in recent days. One such platform is chatX(!), which has gained considerable popularity due to its exceptional capabilities. However, the tech behind chatX remains shrouded in mystery. This paper aims to unravel the tech behind this advanced chatbot, and propose a novel approach to creating similar systems.
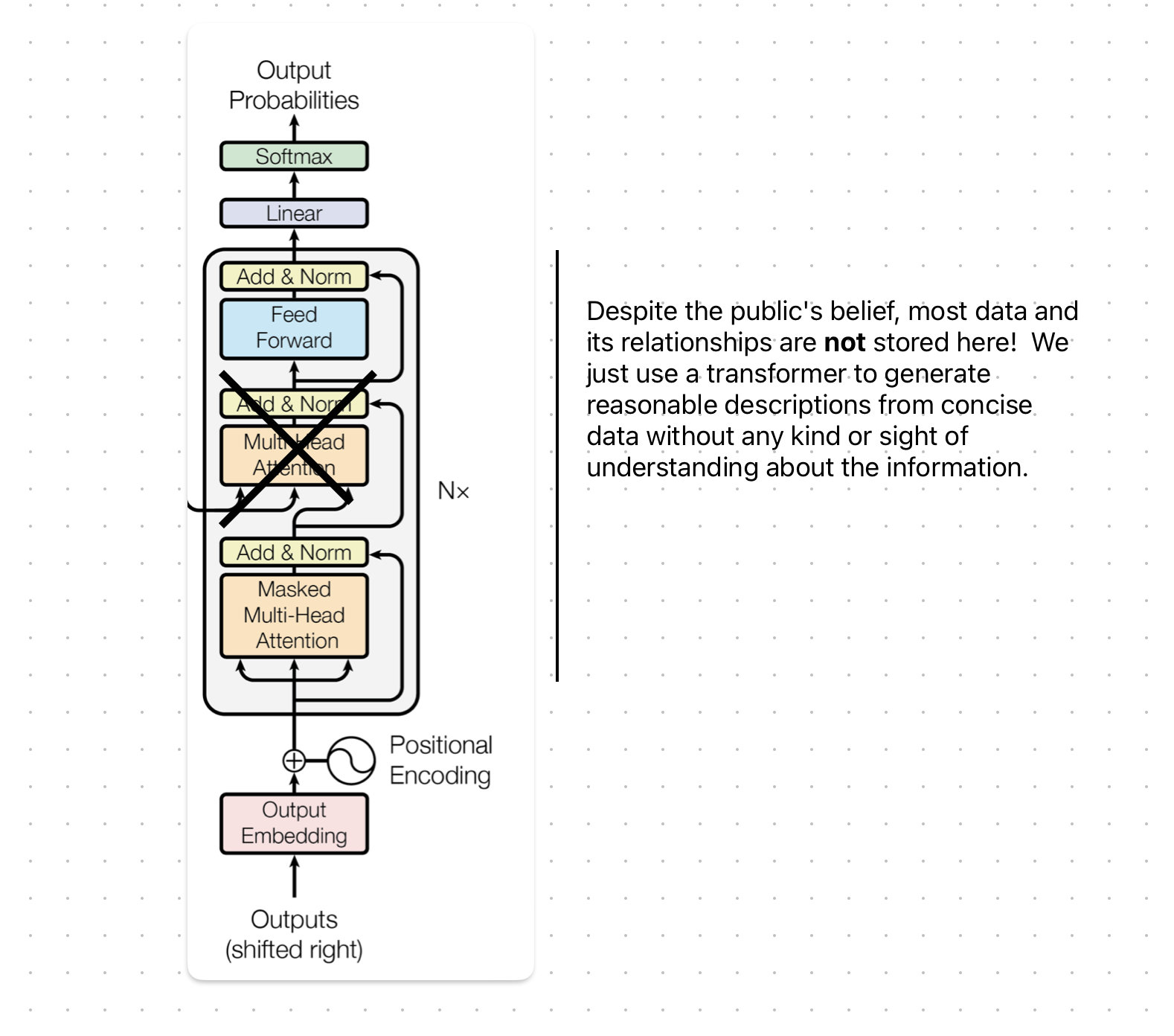
Contrary to popular belief, the key to developing a chatbot like chatX is not storing information in transformer layers. Instead, storing information in a database and creating key/indexed data in a classical DB is essential. When a user inputs a query into a hyper-model, the first step is segmenting the query into sub-intents. This can be achieved by utilizing a linear classical keyword density-based extractor or a non-linear ANN.
Once the query has been segmented, a classical search is performed on a database containing a vast amount of data indexed by keywords, similar to Google. The search returns a set of raw abstract information (R1, R2, ..., Rn) related to the user input. Next, the information is fed into a textual transformer model to generate more detailed explanations for each abstract result. So the input has sight of the raw prompt and information related to them.
However, the most crucial step is determining whether the generated explanation is reasonable for a human user or not. To accomplish this, an adversarial model is utilized, which is trained using reliable resources such as Wikipedia and human-labeled data. The adversarial model decides whether the generated output is acceptable or not, ensuring that the chatbot produces high-quality responses by changing policy or just applying corrections to the output.
Model structure
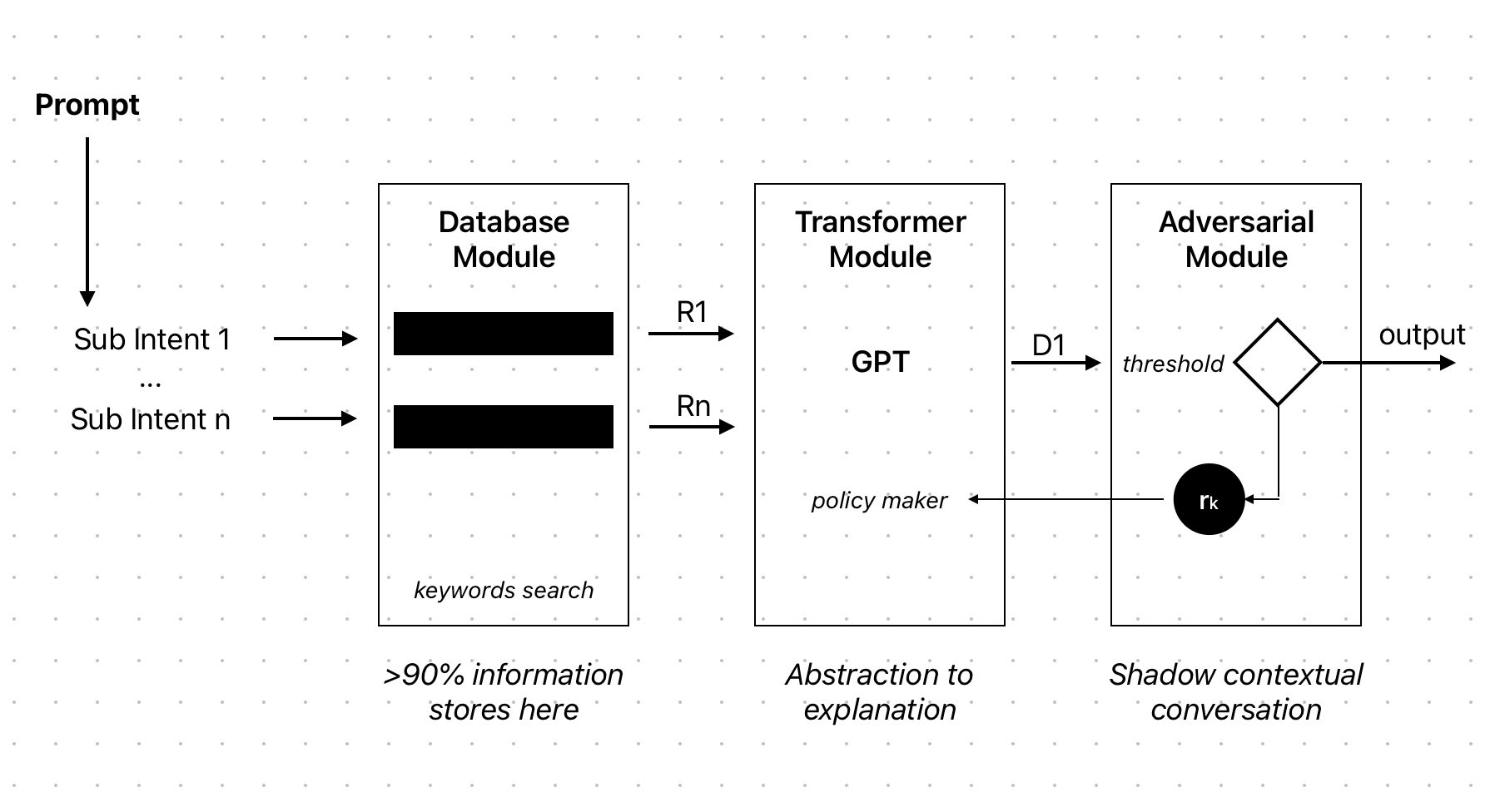
The first stage is a classical search module that utilizes data mining methods to extract relevant information from the internet. This information is then stored in a database, and a graph of relations is created between the extracted data and their associated keys. This module serves as the foundation for the model, providing it with a wealth of information that it can draw upon.
The second module is a transformer known as GPT (Generative Pre-trained Transformer). This module is responsible for generating sequences and descriptions based on the concise output generated by the first module. It is trained on a large dataset and is capable of generating high-quality text that closely mirrors human writing.
The third and final module is an adversarial model that serves as the gatekeeper for the model's output. This module is trained by human-labeled data and is responsible for determining what output is acceptable and what is not. It ensures that the model's output is both accurate and of high quality.
Make Your Business Online By The Best No—Code & No—Plugin Solution In The Market.
30 Day Money-Back Guarantee
Say goodbye to your low online sales rate!