

Day 4. Understand what’s important

AI can be broken down into three main sub-processes: data, structure, and learning.
1. Data: The first step in developing an AI model is to provide the appropriate data. Depending on the type of mechanism being used, this may involve obtaining labeled data or implementing a system for providing feedback.
2. Structure: Once the data has been obtained, the next step is to create a structure for the neural network or any pre-processing and post-processing steps that may be necessary. This includes designing the architecture of the network, as well as any data preprocessing or feature engineering that may be required.
3. Learning: The final step is to train the system, maintain it, and apply some level of supervision. This includes implementing a learning algorithm, such as gradient descent, and adjusting the model's parameters as necessary to optimize performance. Additionally, it also includes maintaining the system by monitoring its performance, updating it with new data, and troubleshooting any issues that may arise.
Personally, I am not interested in creating large artificial neural networks (ANNs) and training them with massive datasets using excessive computational power. This is because companies like OpenAI have already achieved this and it would be difficult for me to compete with the vast resources they have at their disposal. The focus, instead, is on creating efficient and effective models using the available resources and finding creative ways to work with smaller datasets.
Articulate questions
Instead of focusing on creating large artificial neural networks (ANNs) and training them with massive datasets, my goal is to address some of the fundamental unanswered questions in the field of AI and AGI. Understanding these big questions is crucial before delving into the practical implementation of ANNs and attempting to deploy them in the real world.
Some of the key questions I am interested in exploring include:
- Why do we need large datasets to train ANNs, when humans can learn from limited data?
- How can we pre-train ANNs in a more efficient manner?
- How can we expand an ANN from a single-task network to a multi-task and multi-modal network?
- How can we make AI systems self-maintaining and self-progressive?
By focusing on these questions, I hope to gain a deeper understanding of the underlying principles of AI and AGI and contribute to the development of more advanced and capable AI systems.
Recently, I have been focusing on demonstrating how I can formulate hypotheses, implement them and test them in the real world, with the goal of potentially discovering or creating answers to some of the fundamental questions in the field of AI and AGI. I believe that this approach allows me to gain a deeper understanding of the underlying principles of AI and contribute to the development of more advanced and capable AI systems.
How start?
Let's simplify the process by using a camera as the data input, as it provides a vast amount of data and is relatively inexpensive. Instead of using pre-existing datasets, I will explore ways to train ANNs using images fed directly from the camera and using unsupervised learning methods. Then, I will use supervised methods to label certain groups. If you're interested in specific applications like face detection, finger gesture detection, image generation, or AI chat, there are plenty of resources available online that focus on these specific fields.
At this stage, I am using a camera as the data input, a PC with a Radeon VGA graphics card, PyCharm as the development environment, and some knowledge and understanding to test and experiment with the implementation.
Let's work on training a basic perceptron
Training a perceptron, which is a simple type of artificial neural network, involves several steps:
1. Initialize the weights: The first step is to initialize the weights of the perceptron. This is typically done by assigning random values to the weights.
2. Feedforward: The input data is then fed into the perceptron, and the dot product of the input and the weights is calculated. This value is then passed through an activation function, such as a step function or a sigmoid function, to produce the output of the perceptron.
3. Calculate the error: The difference between the predicted output and the actual output is calculated. This is known as the error.
4. Update the weights: The weights are then updated based on the error. This is typically done using gradient descent, which adjusts the weights in the opposite direction of the gradient of the error with respect to the weights.
5. Repeat steps 2-4: The process is repeated for a number of iterations, until the error is minimized.
6. Test: Finally, the trained perceptron is tested on new unseen data to evaluate its performance.
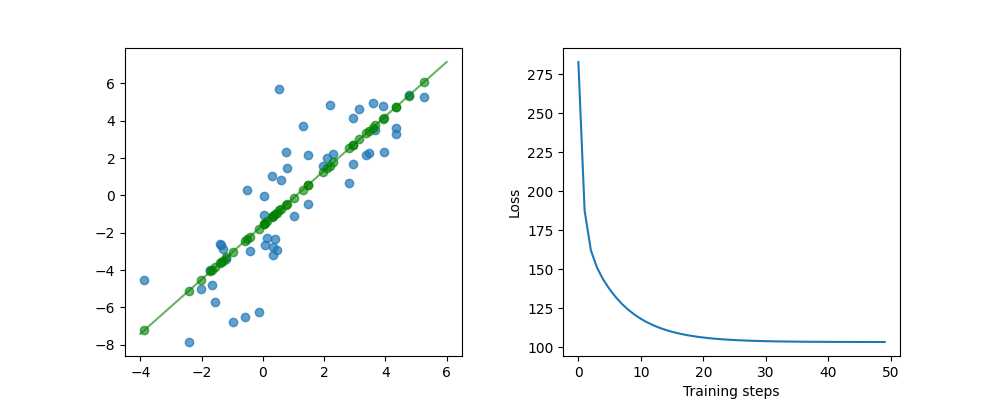
By utilizing the code provided, you will gain exposure to some basic and crucial concepts and libraries that will be utilized in the future AI/ML projects, such as NumPy, Matplotlib, Tensorflow's optimizer and loss calculation functions. These libraries will allow you to avoid re-implementing fundamental functions repeatedly and allow you to focus on the more complex aspects of your projects.
Play with Neural Networks
This is a sample of a simple neural network, using Tensorflow playground you can experiment with different configurations, such as adding layers, changing activation functions and testing it with different datasets. The playground provides a visualization feature that allows you to observe the network's behavior, which can provide valuable insights into how artificial neural networks work.
Tinker with a real neural network right here in your browser.
 Tensorflow
Tensorflow
Exploring the inner workings of your machine learning models with tensorboard
TensorBoard is a web-based tool that allows you to visualize and analyze the performance of your machine learning models, particularly those built using TensorFlow. It provides a suite of visualization tools that can help you understand the training process and identify patterns, trends, and other insights that can help you improve the performance of your models. Download & Guide

Some of the features of TensorBoard include:
- Scalar: visualizing scalar values such as accuracy, loss, or any other scalar values you want to track.
- Histograms: visualizing the distribution of a Tensor over time.
- Graphs: visualizing the computational graph of the model.
- Images: visualizing image data.
- Audio: visualizing audio data.
- Text: visualizing text data.
- Embeddings: visualizing high-dimensional data such as word embeddings.
TensorBoard also allows you to compare different runs of your model, and to compare the performance of different models. This can be useful for identifying patterns, trends, and other insights that can help you improve the performance of your models.
Make Your Business Online By The Best No—Code & No—Plugin Solution In The Market.
30 Day Money-Back Guarantee
Say goodbye to your low online sales rate!